Fundamentals of the digital humanities |
|
The basics of concording by Willard McCarty, King's College London |
|
"We should not ask what the words
mean,
as though they contained secrets,
but what they are doing,
as though they embodied actions."
Denis Donoghue, The Sovereign Ghost: Studies in Imagination, p. 54.
I. Introduction
A. Goals of analysis
In broad terms we read a text in order to understand what it says, analyse it to discover how it says what it says to us. Analysis focuses on the details -- individual words and phrases, patterns formed by these, the contexts required to make sense of the text as a whole. It is concerned with what we do as a matter of course when we read a text but pay little or no attention to directly. It seeks to explain our impressions, trace them back to their causes in the language, or perhaps show us that we were mistaken.
Not all texts are straightforwardly about what they seem or profess to be about. People commonly say one thing but mean another -- because they are lying, unaware or confused, or are dealing with a subject too complex for direct treatment. Analysis may therefore uncover contrary or contradictory meanings in a text, show how a subject is being avoided or is indicated indirectly. A government minister, for example, may be politically constrained not to address a subject about which he or she is apparently speaking; close analysis can show the evasions. A person who is being surveyed may reveal more to the researcher in his or her choice of words and phrases than by explicit statement. Similarly, the author of a report may not see the implications of his or her subject but at the same time betray them in the language employed to write it. A poet normally works by indirection, because the subject of poetry is almost by definition beyond the capacity of any language to capture. Analysis will show how he or she manages, as it were, to speak the unsayable.
B. The concordance
Among the most basic tools of text-analysis is the concordance, "An alphabetical arrangement of the principal words contained in a book, with citations of the passages in which they occur" (OED). The first concordance was made in the late 12th or early 13th Century as a means of marshalling evidence from the Bible for teaching and preaching; concordances for works of secular literature followed much later.
A concordance derives its power for analysis from the fact that it allows us to see every place in a text where a particular word is used, and so to detect patterns of usage and, again, to marshal evidence for an argument. Since words express ideas, themes and motifs, a concordance is highly useful in detecting patterns of meaning as well. The concordance focuses on word-forms, however -- not on what may be meant but what is actually said. It is an empirical tool of textual research.
Until the advent of a computer, concordances were made slowly and laboriously by hand. The physical restrictions of the printed book meant that the concordance tended to be very bulky, its form was fixed and numerous features had to be decided by the editor once for all time. Since the electronic concordance generator produces its output on demand and, within the limitations of the software, can adapt this output to the needs of the moment, it tends to serve the purposes of research much better than its printed analogue.
C.
Text-analysis
Concording is but one kind of rearrangement to which a researcher might wish to subject a text in order to trick out its meaning. One might, for example, wish to list all groups of contiguous words repeated in a text two or more times, or a list of the words in a text ranked in order of their frequency of occurrence, or a chart showing the distribution of specific words across a text. Such transformations of a text, and any others we might devise, are known as "text-analysis". In this part of the course, we will first be concerned with simple concording techniques, then look at some of the more sophisticated kinds of text-analysis.
A rough methodology for text-analysis is outlined in the introductory page "Method in text-analysis" [X]. It is essentially an abstraction of the techniques covered through examples and exercises here.
III. Simple concordancing
A. Basic features
A simple concordance program (or "concordancer") will have the following features:
1. Selection, to specify for which word(s) you want to see a concordance. There are two main possibilities:
§ Wordlist. A concordance program will provide a complete list of words from which to select. Monoconc, for example, lists all words in a corpus alphabetically or by frequency of occurrence.
§ Query. Most if not all concordancers offer a means of generating a concordance based on a query in which you specify the form you want together with optional symbols, called wildcards, to indicate any other letters. If, for example, you wanted to have a concordance not just for the single word-form "bag" but also for the plural and related forms (thus "bags" and other words beginning with these letters, such as "baggage"), you would need to use a wildcard. You would write "bag*" (i.e. "bag" followed by any number of other letters. More complex and powerful pattern-matching symbols known as "regular expressions" may also be available. The query may also allow for
§ proximity searching, in which you specify that you want to see a specific word-form only if it is found within a certain number of words from another word-form you specify. If, for example, we were interested in finding where someone is said to possess a bag, we might want to select all passages in which the word "bag" is found within 5 words of "have", "has" or "had"
§ phrase searching, in which you specify fixed sequences of words to be found, such as "in case of".
2. Lemmatization, to group together word-forms under a single headword (or "lemma").
Even with a powerful query language, one cannot easily group together all the related forms of highly inflected words, such as "go", thus "goes", "gone", "went". One may also need to handle variations in spelling, such as between British and American forms, or accommodate other differences, such as between hyphenated and non-hyphenated forms. Monoconc, unfortunately, does not provide a means of grouping together words according to a common lemma. Concordance, a more sophisticated program, allows the user to create his or her own groups, thus manually to lemmatize variant forms or define a group of synonyms, e.g. "bag*", "luggage", "back-pack", "carry-all".
3. Collocation, to discover what words are found in close proximity to a given word.
The interest in collocation (i.e. the tendency of particular words to co-locate with others) is based on the idea that meaning tends to be communicated not so much by single words as by combinations within a specified distance known as the span. The span varies by language; for English meaningful connections are likely to be found within 5 words on either side of the target-word. Thus, to cite a trivial example, the fact that "the" collocates very frequently with "bag" in a given text, especially to the left of the word, suggests quite strongly that a particular bag is the object of interest.
4. Display, on screen with option to print.
The most popular and highly influential format for concordances is the so-called KWIC, or "keyword in context, in which the target word is centred and an arbitrary amount of context give on either side. Following is a typical example:

Contrast this left-aligned view:

and with this view, in which the context is determined by the natural syntactic unit -- the standard approach in the handmade concordances of the past:

The point here is that we tend to approach the language differently in each case, as a result of which we think differently about it. Format is anything but trivial here. The format of the last example directs us to read each line; as a natural consequence we then want to see more context for those occurrences that interest us. It is a tool for finding relevant passages. The KWIC format of the first example directs our attention to the immediate linguistic environment of each occurrence rather than to the syntactic unit (phrase, clause, sentence) in which the occurrence is embedded. We are invited to inspect what is happening at a lower level than reading, prior to the stage at which we put together the word-forms into units of meaning. It is a tool for studying language.
In brief, format matters. "Shapes are concepts" (Arnheim 1969: 27). In the case of concording, they powerfully influence how we conceptualize language.
5. Sorting, i.e. reordering the displayed according to various criteria.
The KWIC format is made much more effective if we can sort the lines according to the words that occur before and after the selected word, as well as according to the order in which the occurrences are found in the text. Here, for example, is a sorting of "bag" by the immediately previous word:
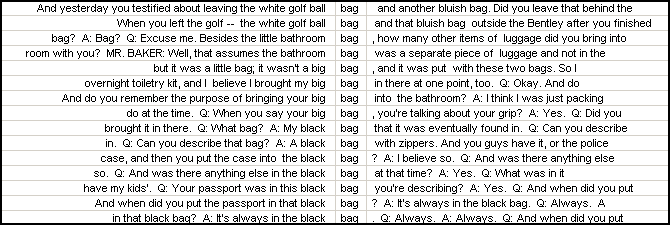
and here is a sorting by the immediately following word:
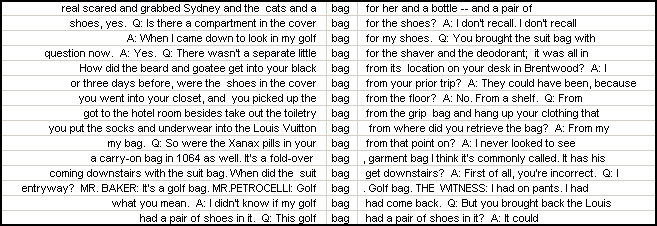
Because of intervening words, it may also be handy to sort the lines by the words before and after the immediately contiguous words, e.g. by the word second from the left, as here:
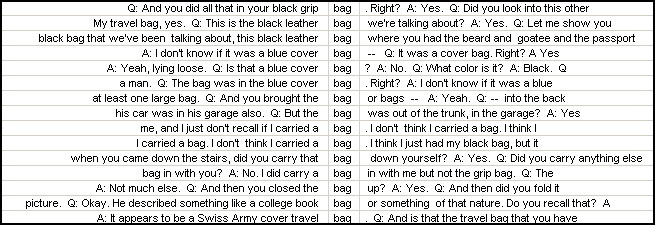
Concordance allows us to sort by the 4 words on either side of the target word and by a number of other criteria.
6. Output, to printer and text-file.
A concordancer should allow you to print the output for ease of reference and to write it as a text-file for further processing. Note that by treating the concordance itself as a text, then concording it, you can study the words within the specified range of context. This is useful in case you want to study collocations beyond the limited span allowed by the software -- especially needful if, say, you were working with a Latin or German text.
B. Other features
1. Frequency lists.
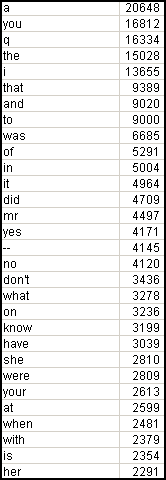
The frequency list is the simplest example of statistical information that may be gained by counting features of the text, then subjecting these counts to mathematical transformations. Frequency lists have been included with alphabetic concordances for a long time, even before concordances were first produced with the help of computing. The basic idea behind a frequency list is that the more frequently a word is used the more likely it is to be important to the meaning of a text and to its stylistics. A frequency list is therefore sometimes useful in detecting the basic preoccupations of a text, especially when these do not coincide with the apparent subject, and for characterising the linguistic habits of the author.
 Literary
and textual scholars have in the past tended to be resistant to enumerating the
components of the artifacts they study, but such resistance does not stand
close examination. The number of times we perceive something in a text, whether
consciously or not, the more influence it has on our reading. Computers simply
make such counting easier, and (with considerable work on our part) they make
statistical ideas accessible to us. The caveat is: be very cautious
about what you claim for your statistical results.
Literary
and textual scholars have in the past tended to be resistant to enumerating the
components of the artifacts they study, but such resistance does not stand
close examination. The number of times we perceive something in a text, whether
consciously or not, the more influence it has on our reading. Computers simply
make such counting easier, and (with considerable work on our part) they make
statistical ideas accessible to us. The caveat is: be very cautious
about what you claim for your statistical results.
A portion of a frequency list is shown to the right. Knowing nothing else about the text from which these statistics have been produced, we can make the following tentative observations:
§ The text is likely to be conversational: "I", "you" and "yours" occur very frequently;
§ It somehow combines the qualities of formality (note "mr") with informality (the contraction "don't");
§ The frequencies of "yes" and "no" suggest questioning and answering. This is reinforced by the high frequency of "q", which might point to a dialogue involving questions. (There are relatively few q-words in English, and even fewer of them would be likely to pepper a text so densely.) Could some of the "a"s similarly stand for answers?
§ The remarkably high frequency of "know" suggests that knowledge is central. Might we be faced with a situation in which someone is being questioned at length about what he or she knows?
Such analysis is hardly profound, but it does demonstrate how much may be extracted from very little data. We will return to this (now hidden) text and the questions raised by this frequency list.
2. Character sets.
Concording languages other than English and Latin requires at minimum the ability to define the accented and other "special" characters (e.g. é, ç, ö) in the Roman alphabet and to determine the order in which they are sorted with the unaccented letters. Processing languages that use other alphabets (such as Greek, Hebrew, Cyrillic) is considerably more of a challenge.
Much of the software written to date has been designed with English in mind and so cannot easily handle accented characters. For concordancing software with particular attention to the problem see Selinker and Barlow.
rev. 9/2002